
The list of criteria and focus questions that follow may be helpful when reading the text and putting together the critical review. Keep in mind to review your assignment guidelines for more detailed standards and focus questions that should serve as the foundation of your review. The number of criteria for evaluating the text-to-image generator you will address in your critique will depend on how long the review or assignment is.
12 Top Criteria For Evaluating Text-To-Image Generator
1) Significance and contribution to the field

Some possible inquiries for this standard are:
-What is the writer’s purpose for using a text-to-image generator?
-How well has this objective been accomplished?
-What new knowledge does this text add to the field? This could relate to theory, data, or a real-world application.
-What connections does create text-to-image have to relevant earlier works?
-What is omitted or left unsaid?
-Is this a difficulty?

2) Methodology or approach

Some possible inquiries for this standard are:
-What methodology was applied to the research? For instance, comparative, case study, qualitative or quantitative research, analysis or review of theory or current practice, etc.
-How neutral or biased is the method?
-Are the findings credible and valid?
-What analytical framework is applied to the outcomes discussion?
3) Argument and use of evidence

Some possible queries for this standard are:
-Is there an obvious issue, claim, or hypothesis?
-Which assertions are made?
-Is the thesis coherent?
-What types of evidence are used in the text?
-How trustworthy and valid is the evidence?
-How persuasively does the evidence back up the claim?
-What inferences are made?
-Do these conclusions make sense?
4) Writing style and text structure

Some possible inquiries for this standard are:
-Does the writing style appeal to the target reader? For instance, academic/non-academic, expert/non-expert, etc.
-What serves as the text’s organizing principle? Could the organization be improved?
5) BLEU: Bilingual Evaluation Understudy Score
The most widely used evaluation metrics for contrasting models in the NLG domain are BLEU and Rouge. These metrics will always be reported in every NLG paper using common datasets. The n-gram overlap of the reference and generated texts from a text-to-image tool is calculated using the precision-focused metric known as BLEU.
This n-gram overlap indicates that, aside from the term associations of n-grams, the evaluation scheme is independent of word position. One thing to remember about BLEU is that when the generated text using a text-to-image tool is too short compared to the target text, a penalty is applied.
6) Rouge: Recall-Oriented Understudy for Gisting Evaluation

Another commonly reported metric is rouge, as was already mentioned. Reporting Rouge along with BLEU ratings for common tasks is a relatively common practice. The only difference between Rouge and the BLEU definition is that Rouge is recall oriented while BLEU is precision-focused.
Another commonly reported metric is rouge, as was already mentioned. Reporting Rouge along with BLEU ratings for common tasks is a relatively common practice. The only difference between Rouge and the BLEU definition is that Rouge is recall-oriented while BLEU is precision-focused.

Rouge comes in three different varieties. N-rouge, the most prevalent rouge type, refers to n-gram overlap. eg. For 2-grams and 1-gram, respectively, use a 2-rouge and a 1-rouge. The second is l-rouge, which instead of looking for n-gram overlap, looks for the Longest Common Subsequence. S-rouge, which focuses on skip grams, is the third. Most ML libraries have standard implementations of these; n-rouge is the most widely used. The n-rouge source code is provided below.
7) Perplexity

Perplexity, a popular metric for assessing the effectiveness of generative models, is used as a gauge of the likelihood that a sentence will be generated by a model of a text-to-image tool that has been trained on a dataset. The ability of a probability distribution to forecast or assign probabilities to a sample is referred to in information theory as perplexity. The better the model, the lower the perplexity value. On the basis of sentence length, complexity is normalized.

In order to select the language model with the lowest value for this metric, we will ultimately check perplexity values on the test set. This means that you should pick the probability model that gives the test set phrases a high likelihood of being true.
In the worst case scenario, where the model is completely illiterate, perplexity equals |v|, or the vocabulary size.
8) METEOR: Metric for Evaluation of Translation with Explicit Ordering
Uncommon metric METEOR analyzes word alignments. It calculates word mapping from reference texts and generated text-to-images that is one to one.

It typically makes use of Porter stemmer or WordNet. Finally, it uses these mappings to calculate an F-score. Since the popularity of deep learning models has increased, meteor is a metric in NLG that is used much less frequently.
9) TER: Translation Edit Rate
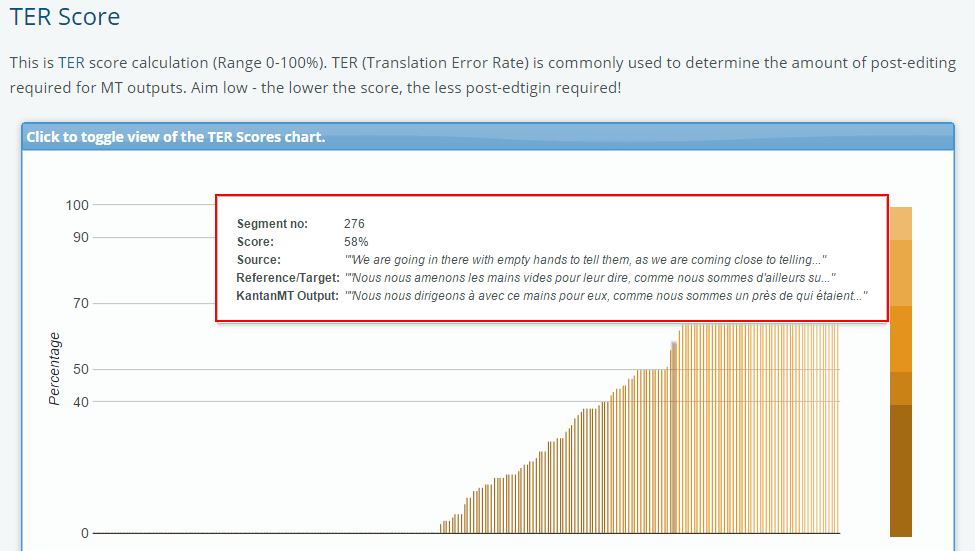
The basis of TER’s operation is the conversion of generated text to target text. Counting the number of operations necessary to change one string into another calculates the absolute difference between the strings. It is very similar to the Edit Distance algorithm.
10) Generative Adversarial Networks for AI Image generator

The original GAN suggested it is made up of two neural networks: a text-to-image generator network G(z) with noise z Pz sampled from a previous noise distribution, and a discriminator network D(x), where x data are real data and x pg are created images, respectively.
The training is designed as a two-player game in which the discriminator is trained to discriminate between created and actual images while the generator is trained to take advantage of the real data distribution and create images that deceive the discriminator.
The cGAN objective function was enhanced in a variety of ways to enhance conditional GAN training. For instance, the inventors of AC-GAN proposed that the discriminator be given an additional classification loss, as LC.
11) Attention Mechanisms of AI-Generated Text-To-Images
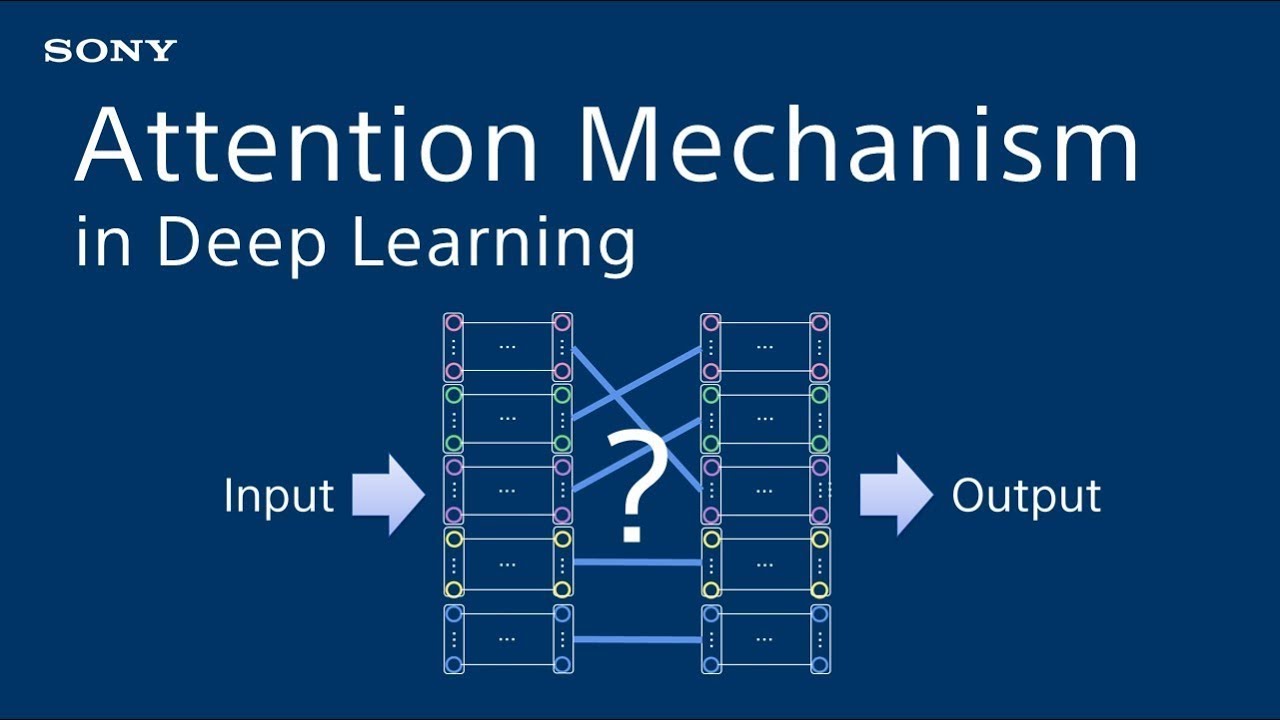
Using attention strategies, the network can concentrate on particular components of input by giving significant components a higher weight than irrelevant ones. The development of language and vision applications has greatly benefited from the use of attention [50, 51, 52, 53]. The multi-stage refining pipeline in AttnGAN [35] involves attention and builds on StackGAN++ [40]. In addition to the overall sentence vector, the attention mechanism enables the network to synthesize fine-grained features depending on pertinent words.
12) Adapting Unconditional Models of Text-To-Image Generation
Numerous research proposed to modify the design of these unconditional models for conditional T2I production, building on advancements in unconditional capacity in generating text-to-images. The creators of textStyleGAN expanded StyleGAN, a T2I model that can produce graphics at a higher resolution and supports semantic manipulation. A pre-trained image-text matching network and text-to-image generator, similar to the one used in AttnGAN, was suggested by the authors to compute text and word embeddings. They also suggested concatenating the sentence embedding with the noise vector before conducting a linear mapping to create an intermediate latent space of ai generated image.
Additionally, they make use of the text-to-image generator’s word and image elements for attentional guidance. Cross-modal projection matching, in addition to unconditional and conditional losses in the discriminator (CMPM) and losses, is employed to match input captions with produced images in cross-modal projection classification (CMPC) systems. Finding the directions in the intermediate latent space that correlate to semantic qualities like “age” and “smile” for face photographs can be the first step towards manipulating an image. Given that StyleGAN’s intermediate latent space
It has been empirically demonstrated to unwarp the initial latent coding, causing the components of variation to become more linear and enabling sampling, which in turn enables semantic image modification. These criteria are a major deal in an ai art generator to generate ai art with multiple features such as creating multiple images and text prompts that can improve the quality when you generate pictures.
Best Text-to-Image Generators
| Product Image | Product Name / Primary Rating | Primary Button |
|---|---|---|
|
|
|
|
|
|
|
Conclusion
The difficulties of visualizing a tale text with numerous characters and typical semantic relationships were discussed in this article. Two cutting-edge GAN-based picture creation models served as inspiration for our two-stage model architecture, which we used to propose a novel method for images created.
In order to direct the image-generating process toward creating more insightful and realistic images, we used the object layout module. Through in-depth analysis and qualitative findings, we showed that our method can produce an image of very high quality that accurately depicts the text’s main objects. While completing the fine-grained image generation by a text-to-image tool in stage II, the object layout module can control the location, size, and object category.
Delving deeper into a wealth of knowledge and insights awaits you within our extensive collection of blogs. These thoughtfully crafted articles serve as a treasure trove of information, providing a comprehensive exploration of various topics. Whether you seek to broaden your understanding of cutting-edge technologies, stay abreast of industry trends, or gain valuable tips for personal and professional growth, our diverse range of blogs caters to an array of interests.
FAQ
How long does the conversion process usually take when employing an AI picture generator?
The turnaround time ranges from a few minutes to a few hours depending on the size, type, and required conversion of your source document. Smaller documents can be processed fast. A lengthy document, such as a textbook in image-only PDF, may take many hours to convert to a Microsoft Word file or an MP3 audio file.
Can I create numerous photos at once?
Yes, it is the solution. Text-To-Images can be generated concurrently using Fotor’s Al drawing generator. You can choose the one from the group that best suits your needs. It quickly generates graphics using artificial intelligence. These text-to-image generators develop concept art, generate images, create numerous images, and generate artificial intelligence (AI) art using latent diffusion models.
What distinguishes “PDF – image over text” from “PDF – text over the image”?
There are two options for converting PDF and image-type documents into tagged PDF in the drop-down menu under the accessibility conversion options section of some text to image ai generator or SensusAccess online forms: “pdf – Tagged PDF (text over image)” and “pdf – Tagged PDF (image over the text)”.
By selecting the first option, OCR processing will be applied to PDF and image-type documents, and the output will include the text that was recognized as a layer over the original image.
By selecting the second option, OCR processing will be applied to PDF and picture-type documents, and the results will be returned with the original image overlaid over the recognized text. The quality of text recognition is the same for both settings.
When the recognized text is displayed over the original image, the text will typically be noticeably sharper. But occasionally, logos and other graphic elements appear distorted or hazy.
When the original image is displayed over the recognized text, all of the original graphic components are kept, but the text’s visual presentation is not sharpened.




